
Salil Mehta is a statistician and risk strategist. He served for two years as Director of Analytics in the U.S. Department of the Treasury for the Administration’s $700 billion TARP program. Salil is on the Editorial Board for the American Statistical Association, is a Chartered Financial Analyst, a fellow member of the American Statistical Association and Royal Statistical Society, as well as being a current dual candidate member of the Society of Actuaries. He is the author of the mathematics book, Statistics Topics.
~~~
In the age of “big data”, technology companies are positioning themselves to allow humans the ability to more easily answer previously inextricable problems with interesting techniques. And while there have been some silent successes -where advanced techniques have been largely embedded into organizations without fanfare- there have too been a too many recent high-profile failures where companies sloppily lumber forward and collapse over their own untied shoelaces.
Examples are from the academically “gifted” teams behind Google’s Flu Trends, facebook’s secret experiment, Apple’s map software, 23andMe’s genetics business, and Kensho’s Santa Claus rally call. Maybe we should add Microsoft’s HowOldRobot onto this naughty list. Their playful tool was enjoyed all over the world this month, but does it truly create a better guess as to your age? Here we seek to mathematically answer at what point should we reward only true precision and not what any probabilist can discern as a blooming, random number generator.
Somewhat aware of this point, their product claims to just know “how old do I look?” instead of something more relevant, which is “how old am I?” Clearly they haven’t a clue about the latter- and to be fair it is a near impossible task that few of us would rationally claim we can really do. But we assume most people collectively look how old they actually are. Else -for example- if all babies suddenly looked like senior citizens (think Benjamin Button), then people would quickly adjust their perception of what a baby looks like (newborns simply would have the “senior citizen” age look) and that appearance would then become what everyone associates back to a baby’s age instead (so no one could really look the age of a “senior citizen”.) The idea of not knowing one’s age, but instead guessing at how old they looks, is filled with relevant follies, as we will soon see with actual output.
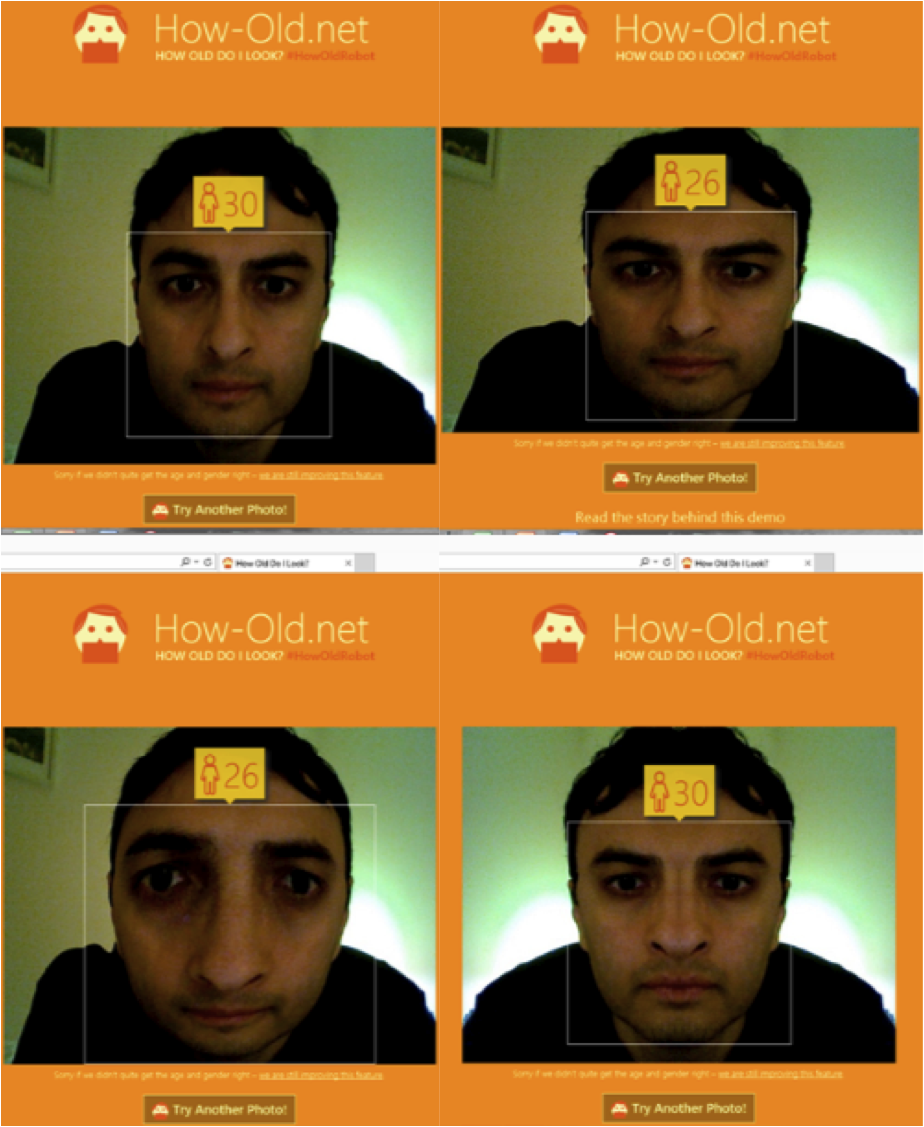
We’ll return to the other three pictures above, after first discussing some mathematical theory. An important thing to state here is there are ways to link the work done here by HowOldRobot to some quantitative understanding of the uncertaintybehind these guesses. Microsoft would have been better off providing us with the confidence interval range behind this, but such a result would have been awful transparency for their marketing! But still we can use probability theory to understand that at the heart of this application, they are seeking only a small number of clues about the individual. Despite all of the information exposed through a face, the science comes down to thinking about a straight image -in many cases- and what might be the gender or race of the individual. It would also glean from the image properties, the random selection of colors and granularity provided to it, and combined with facial changes over time provide an overall guess on age. Such judgements would process -say- that a celebrated centenarian will be more wrinkled versus a baby.
Empirically this sort of probability problem concerning life age, can’t be theoretically solved in closed form. The life tables that invariably drive this behind the scenes employ census information and are similar to actuarial tables. Hence we must use logical information about the representative population of internet users and their likely cohorts, which Microsoft is making the age guesses for. See our article here for information on the difficulty in modeling customized actuary functions, even though it is certainly possible at times and under proper guidance.
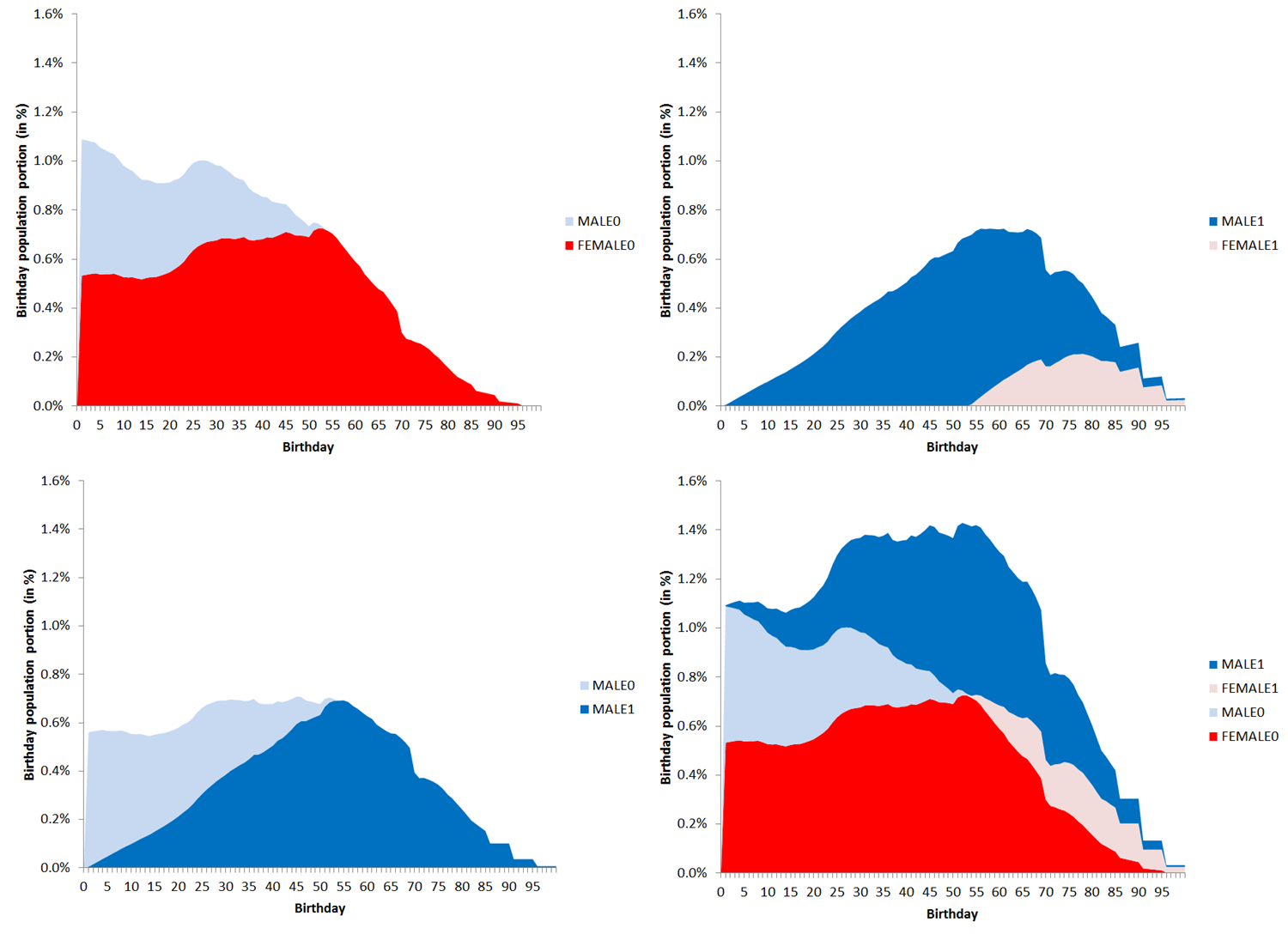
To appreciate the conditional life population likelihoods, just see any of these two below, to get a sense of the distribution layout, by gender (male or female), and by children/youth versus mature/older (0 versus 1). For demonstrative ease, the small and censored fraction (<.05% and nearly all are women) of the global population aged >100, have been categorically truncated for this exercise. The topic of censored-data treatment, through statistical modeling, will be dealt with in a later blog article. For now, we can also see and appreciate the dearth of recent births in the recent global financial crisis. The complete chart, with all four mutually-exclusive and completely exhaustive population segments added to one another, is shown on the lower-right.
Here is the distribution below for just half the typical partitions based on facial bone changes hat Microsoft’s application would be making, with the typical age (and just as important the conditional standard deviation):
older male – 33%, age 50 (19)
older female – 6%, age 75 (10)
younger male – 16%, age 18 (13)
younger female – 45%, age 38 (21)
Technically speaking, a dart-throwing monkey or anyone would not simply guess anywhere along the entire population age distribution, but rather focus on the component, or zone, sharing the same basic statistical characteristics of the “matching” face. One might ask if, say a trained monkey, throwing a dart wouldn’t just aim for the center of such a large and unwieldy distribution shape. That would be incorrect interpretation of our probability analogy. For those readers, instead picture the entire (sub)distribution partitioned into 20 or 100 equal sized spokes. And now each one of those is used to complete the dartboard design, of same number of spokes. The monkey would then blindly aim for the dartboard (the board could be spun along its center if that’s a concern).
Of course we know the subdistributions of the population (e.g., each colored segment above) is unequal-weighted to begin with. This is just to be analytically complete in describing the random process the computer goes through. The computer does not simply, randomly guess and model off of the entire distribution. This is similar to say FICO credit scores, where the computer seeks first to isolate the user into (legally it must be very rudimentary) demographic buckets first, and then more finely guess the parametric characteristics for each group. In the end, we hope the entire “model” works, but the proof is only seen in the output, and without Microsoft providing an actual confidence interval, we on our own here collect and demonstrate their flawed out-of-sample results.
This of course is not an issue only for the author, but across the entire human population, where even a correct answer could have been a false negative (e.g., a lucky guess). Let’s look at other important contortions, on different types of people. We’ll look at Hollywood actresses, a group that is selection biased towards a segment whose very career survival depends on “being young”. Clearly Microsoft, if anything, would always err on the side of looking younger when guessing at this cohorts. But there too, it instead spectacularly at times (nor can it account for pervasive plastic surgery and other artificial deformities).
But look at this Andy Warhol impression of one of his most illustrious muses, Marilyn Monroe. What would be your age guess on this?

First, HowOldRobot doesn’t even recognize a face in the upper left. But then working clock-wise, it concludes these ages for the other equal portraits: 53, 66, 72. Ouch! Now all the guesses are horrible, wrong in the same direction, and the worst offender was a guess at 72 (twice the age at which she died.)
We noticed earlier that the conditional gender probability is not equal. Notice the two upper distributions in the four-some further above. Notice the blue colored male distribution and how for a main segment it must often compete in the middle age categories, with the larger female populations (in red and pink). This only means that on the margins, the “advanced” robot can confuse a middle-age man with a female. Despite the current cultural focus on make-up and beauty, we can see from the information supplied above, that female faces ages faster over their lengthier life-spans. And the false-positives exist in both directions.
Let’s return now to the popular news above, concerning the wrong-doings of James Franco. How did Microsoft’s age-guessing application even work on him?

Actually, do you mean her? That’s right, blame it all on a sloppy trumpeting of “machine learning”, but Microsoft pegs James Franco at 8 years older than reality (which is relatively a lot) and also has James guessed to be one hirsute woman. This should not fit nicely into their disclaimer about “not getting the age and gender quite right”.

To briefly detour, this is similar to a popular idea to what was created by a 20th-century Harvard statistician, self-namedChernoff’s faces. Unlike changing dot-markers or line types, the complex face can capture and communicate cues that serve as feature variables. A human might see Chernoff faces in any physician’s office, where only a single dimension is used to express happy through sad. By simply altering the value of the mouth and eyes, along the illustration, and the patient pointing to the facial expression they most relate to. We can see below that an adjustment can also be made in a small number of other ways, say to the length and width of the face, as another measure to communicate. Note that touting the transformation of a high-resolution, color imagery that exists today is overboard when the Microsoft age-guessing errors are this bad.

Returning now to the above scientific computer capture of the author, in blue. The properties here could have the potential of a binary indicator value at each point along the image, reducing all of the easy to understand face information to quick security print in the magnitude of ~2(40*50) combinations. Unfortunately this is still too much information and too costly to store and retrieve. So instead the science migrates to a lower magnitude of roughly ~290. One of the weaknesses of the machine learning approach is that it assumes that every data set has the capability to be addressed meaningfully through it’s process. Sometimes the products are still far off from being an important tool, one that the underlying science and math hasn’t been well recognized for, and won’t be unless further technological and mathematical advancements can be made.
Imagine the whimsical and brute force nature of mixing together Play-Doh, which comes with the individual colors segregated into different containers. Anyone can mathematically present a color model at he time of purchase, where each container equals separates and explains a single color. Put a few colors side-by-side, and a traditional linear model makes sense still (similar to a magician using parallel and linear blades to saw through a volunteer in a box). Now we will think about things more complicated representative of real world data. Say the elegance of the Chinese philosophical symbol 太極圖 (known as yin and yang in modern culture). Advanced mathematicians can still come up with a more sophisticated mathematical expression to bisect the two opposing colors there.
But now imagine a more complicated, and somewhat spurious, kneading of the different Play-Doh colors. One can then have a final assembly of a product that is merely too complicated to model the colors from the amalgamation, even as the compact exterior mold looks seductively benign.

It took modern artist Jeff Koons 20 years to put this together. Twenty years is greater than the standard error of some of the subdistribution life estimates above! What linear traditional mathematical model could pierce through such a stunning, multi-dimensional Play-Doh expression? As an advanced probabilist, it is easy to conclude there is none. And it is improbable that we can use sophisticated machine learning and big data to finely explain the location of each of the like colors, as if they were from a simple, non-porous unit. These are life limitations that scientists and business people can run into trouble if they chase too hard against a bad problem.
Big data algorithms don’t care about mathematical precision so much. They are too quick to estimate random art and too glacial to express the expense and errors in the value they presume to create by following their procedures. They would have you believe that every museum exhibit, concerning something similar with Play-Doh, would look similar. That there is a mathematical logic and meaning to almost everything. Put differently, their interpretation of the artistic and multi-dimensional model above is that every color is in a certain place for a reason, similar to the fundamental, ex ante logic we had for the colors in the population distribution manufactured earlier in this article. But this is a run-away fantasy that doesn’t work.
Even as Microsoft’s model aims (and successfully does to a partial though insufficient degree) to reduce the variability in age guessing, from a universal set of the population, we showed here that the conditional volatility allows for heterogeneous errors in large, pre-defined segments of the population at any point in time. This makes to any reasonable quantitative person, the Microsoft product oddly fail versus how it is advertised. It also completely fails in different ways as could have been generally been predicted, and presents a definite, permanent setback and visible weakness of machine-learning algorithms in their instability to be rolled-out broadly. The product failed unaccountably (by Microsoft anyway) with this author. And with Andy Warhol and Marilyn Monroe. And with James Franco. Social media is populated with other cases of breakdown.
In the final analysis, it will always be wiser counsel for companies esteemed as Google and Apple and Microsoft, to operate and promote within their confines of what’s possible, given the technical and resource gaps that exist. Gaffes are not only avoidable, but for large-stakes risks we need to secure the public’s trust. They should have known this product is merely a pleasure tool, and broadly acknowledge the incapability of its precision to happen in at least this innovation cycle. Instead they expose the gimmick of how sensitive these seemingly advanced products are to wild errors, and leave a sensible public perplexed.
We noticed as well, both here and generally in life, that faces are extraordinarily beautiful and complex. As an artist they are highly difficult to even draw and explain. Clearly probability and statistics have a place in cracking the riddle behind how they work. One day we might wrest control -to a robot- of quick and life-threatening decisions anywhere in the world. These errors will no longer be a source of pleasure, but rather imply real lives were sacrificed. Right now you wouldn’t want a monkey as a TSA agent, on guard to check airline passengers ID and highlight suspicion. We could all appreciate the nuisance and aggravation caused by errors. Statistical false-positives (people routinely being inconvenienced) and false-negatives (threats that always go undetected) are both frequent, costly, and will lead to hazardous vulnerabilities. Unfortunately, we operate in a commercial world where Watson and Deep Blue are forced only through brute force (not through something advanced and clever) to stay ahead of humans, but then are advertised as proof that technology companies today can easily solve everything important. Such as strangely state something that no human alive would: falsely concluding with all of Microsoft’s advanced horsepower, that James Franco is actually an older woman.
