
One hundred years of Current Employment Statistics — an overview of survey advancements
John P. Mullins
BLS, August 2016
To help mark the Monthly Labor Review’s centennial, the editors invited several producers and users of BLS data to take a look back at the last 100 years. In 1915, the United States was just beginning to develop as a global economic power. Feeling the need to accurately measure employment in this emerging economy, BLS published a modest set of data on employment in four manufacturing industries. Eventually, this initial effort would evolve into the Current Employment Statistics (CES) program. This article summarizes changes in the CES program over the past century, during which the size, stature, and scope of the survey have grown alongside those of the country whose economy it measures.
Employment estimates from the U.S. Bureau of Labor Statistics (BLS) Current Employment Statistics (CES) survey are among the world’s most watched economic data.1 Monthly data released by CES are used by federal and state government policymakers, central bankers, the business community, and trade unions. It is exciting to consider, then, that this prominent program originated 100 years ago, starting with the publication of data for just four manufacturing industries.
At the beginning of the 20th century, the primary source of data on employment by industry came from a census of manufactures, which was conducted every 5 years by the U.S. Census Bureau. By 1915, many states were compiling manufacturing employment statistics, but only Massachusetts, New York, and New Jersey had reasonably complete data, and, because of industrial specialization in these states, these data failed to accurately represent manufacturing employment on a national basis.
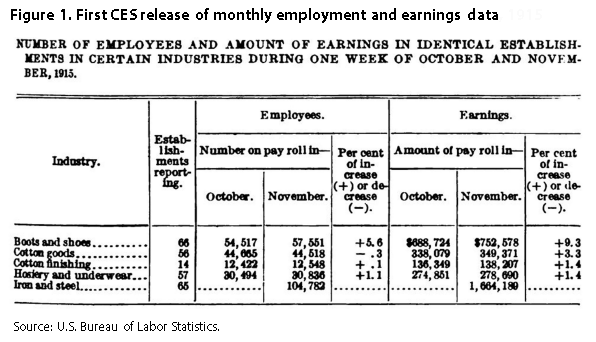 The first issue of the BLS Monthly Review(later to become the Monthly Labor Review), published in July 1915, featured employment statistics for a variety of countries. Upon publication, it was apparent that data for the United States were far less complete than those for countries such as Great Britain, Germany, and France. To address this deficiency, 3 months later, BLS began to publish monthly data on employment and total payrolls for the boots and shoes, cotton goods, cotton finishing, and hosiery and underwear industries, marking the beginning of the modern-day CES survey. (See figure 1.) Today, the CES program surveys approximately 623,000 worksites and publishes well over 10,000 data series. This article outlines some of the key advancements of the CES program over the past century.2
The first issue of the BLS Monthly Review(later to become the Monthly Labor Review), published in July 1915, featured employment statistics for a variety of countries. Upon publication, it was apparent that data for the United States were far less complete than those for countries such as Great Britain, Germany, and France. To address this deficiency, 3 months later, BLS began to publish monthly data on employment and total payrolls for the boots and shoes, cotton goods, cotton finishing, and hosiery and underwear industries, marking the beginning of the modern-day CES survey. (See figure 1.) Today, the CES program surveys approximately 623,000 worksites and publishes well over 10,000 data series. This article outlines some of the key advancements of the CES program over the past century.2
Data publication
Since the inception of CES, federal government commissions, statistical associations, and economic circumstances helped the program expand its industry coverage and types of data published. In 1916, CES published data for nine additional manufacturing industries, and the sample size grew to 574 establishments, covering employment of 519,000. Then, in response to a committee on employment statistics appointed by President Warren G. Harding, the program was again expanded in 1923, to 52 manufacturing industries. Six years later, in 1929, the American Statistical Association recommended a further expansion of industry employment coverage, and publication began for 11 nonmanufacturing industries. To accommodate this expansion, CES increased the sample size to 34,000 establishments. The collection of production-employee hours started in 1932, and CES began to publish data on average weekly hours and average hourly earnings, as opposed to the total gross payroll hours that had been published initially.
By 1935, CES was publishing series on employment and total payroll, hours, and earnings of production employees at the national level for total manufacturing, and the coverage expanded to 90 detailed manufacturing industries and 21 nonmanufacturing industries. In 1936, CES published its first national estimate of total nonfarm wage and salary employment.
Responding to the economic demands brought on by World War II, CES introduced data series for 67 additional manufacturing industries. These were industries that were deemed important to supporting the war effort. Also notable was the introduction of semiannual data on the employment of women in manufacturing, although this series was soon discontinued because of postwar federal budget reductions.
In 1947, the 1945 Standard Industrial Classification (SIC) system was implemented for manufacturing industries, replacing a classification based largely on systems used by the Censuses of Manufactures and the Censuses of Businesses taken in the 1920s and 1930s. Nonmanufacturing industries were classified in accordance with the 1942 Social Security Board Classification. In 1958, the SIC system was adopted for all industry series published by BLS. That system, with periodic updates, remained the basis for CES classification until it was replaced with the North American Industry Classification System (NAICS)3 in 2003. The expansion of the sample to include all nonfarm nonmanufacturing industries began in 1964, allowing for the first publication of average hourly earnings at the total private level in 1967. In 1971, an hourly earnings index for production workers was published. CES diffusion indexes, which measure the dispersion of employment change across industries (rather than the magnitude of that change), were introduced in 1974. In 1988, new diffusion indexes, with a broader industry base, and an additional index for manufacturing were published.
In response to recommendations from the National Commission on Employment and Unemployment (also known as the Levitan Commission) in 1979, the CES program published real average hourly earnings—earnings adjusted to account for price changes—for the first time in 1982. That same year, addressing the Levitan Commission’s finding that CES industry detail was inadequate for the large and growing service-producing sector, CES expanded its sample size and began the publication of data for 82 additional service-sector industries.
In 2003, the CES survey underwent a major redesign. In addition to introducing substantial sample and methodological changes—discussed elsewhere in this article—CES shifted from an SIC-based to a NAICS-based industry classification. Because of this conversion, time-series histories were reconstructed at that time.
In 2004, CES began planning for the collection and production of hours and earnings data for all employees—data that had previously been produced only for production and related employees. Because collection of these data would increase the burden on survey respondents, in 2006 CES discontinued the collection and publication of employment estimates for women employees. CES further planned to eliminate the collection and publication of employment, hours, and earnings data for production and nonsupervisory employees. After receiving more than 5,000 letters of complaint concerning the elimination of women-employee data, CES reinstated this series in 2007 and shelved plans to eliminate production-employee data. In 2008, CES began to publish experimental all-employee hours and earnings series for the nation and, in 2011, the program began to publish official all-employee hours and earnings for the nation, states, and metropolitan statistical areas. So, a survey started a century ago with the publication of employment data for 4 manufacturing industries has grown to cover more than 900 industries. And the data scope of the survey—in 1915, only employment and gross payroll data were published—has grown as well. At the national level, the CES program currently produces over 2,200 employment series, over 2,600 hours and earnings series, and about 8,700 special derivative series,4 such as average weekly earnings, various indexes, and constant-dollar earnings. And at the state and metropolitan statistical area levels, CES produces over 19,000 employment series, over 2,700 hours and earnings series, and about 1,300 derivative average weekly earnings series.
Sample design
Today, the CES sample is a simple, stratified random sample of worksites—a design that reflects contemporary standards for sample-based surveys. One hundred years ago, however, probability sampling5 had not emerged as the standard for such surveys, and, during the first few decades of its existence, the CES survey had no formal sample design.
The early survey predominantly measured employment in selected manufacturing industries, which were dominated by large firms. Therefore, even in the absence of a uniform survey design, sampling the large firms resulted in adequate coverage of the universe. As the survey expanded into the service-providing industries, which were dominated by smaller firms, this approach was no longer sufficient.
In the 1940s, research focusing on this deficiency determined that substantial improvement could be realized by stratifying the sample into two size classes and using a ratio estimator. This was a movement toward probability sampling, without actually introducing a probability sample. The approach was validated by research conducted in 1963,6 but this research also suggested that the most practical course—given the cost, risk, and difficulty of soliciting an entirely new sample—was to implement a quota design7 using the current sample. Quota samples are so called because sample units are selected on the basis of a quota, or predetermined characteristics. These characteristics are assumed to occur in the same proportion in the sample as they do in the entire population. The accuracy of a quota sample depends on those administering the sample and their knowledge of the distribution of relevant characteristics in the population. For CES estimates, the sample was stratified by state, detailed industry, and establishment size. This sample design was first implemented in 1964, although CES recognized that the sample was skewed toward larger firms and that, as a nonrandom sample, it might not represent the universe. The quota sample was used by BLS throughout the 1970s and 1980s, with only minor modifications.
Randomly drawn samples help reduce bias resulting from some members of the population being less likely to be included in the sample. A random sample is more likely to be representative of the universe because random selection balances out both the known and unknown characteristics of a population. CES began moving toward implementing a probability sample in the early 1990s. At that time, probability sampling had been the statistical standard for nearly 50 years, but considerations such as cost, time, and a need to maintain historical time-series data had held CES back from implementing one.
The impetus for examining the feasibility of implementing a probability sample came from an unusually large benchmark revision8 in March 1991. Although sample design ultimately was not found to be the cause of this revision, a BLS-commissioned study by the American Statistical Association recommended a move to a probability sample. Following this study, the CES program began extensive research to develop a probability sample that would be both cost effective and technically rigorous. This research resulted in the gradual implementation of a CES probability sample, with wholesale trade being converted to it in June 2000, goods-producing industries in June 2001, and the remaining industries in June 2002.
Data collection
Initially, all CES data collection was done by postal mail, using monthly collection forms. In 1930, the CES survey adopted a 6-month “shuttle” collection form—so called because the form shuttled back and forth between CES and the respondent. In 1938, a 12-month shuttle form was introduced.
CES gradually evolved into a federal–state cooperative program, with cooperative agreements existing with all states by 1949. State workforce agencies (then known as state employment security agencies) eventually took over nearly all data collection. Using guidelines from CES, individual states also enrolled new establishments into the sample. Throughout the years, state workforce agencies became, and remain to this day, a vital part of the program. Although their explicit roles have evolved over the years, these agencies have adapted and continued to greatly affect CES.
State data collection predominated until the early 1990s, when BLS began to introduce new, electronic data collection methods that it had begun researching and testing during the 1980s. These electronic methods required specialized hardware and software infrastructures and, in many cases, were more cost effective in a centralized environment than in a decentralized setting requiring infrastructure in each state. The most prominent new collection methods included the following:
- Computer-assisted telephone interviewing (CATI), which provides prompting information and data capture to survey interviewers collecting data by phone.
- Touchtone data entry (TDE), in which survey respondents submit data through an automated telephone interview.
- Electronic data interchange (EDI), in which companies submit large payroll datasets, which are then processed to conform to CES reporting formats. (Currently, EDI is the most widely used data collection method.)
- Fax reporting, in which respondents submit a data collection form by fax.
- Web reporting, in which respondents use an online form to submit data.
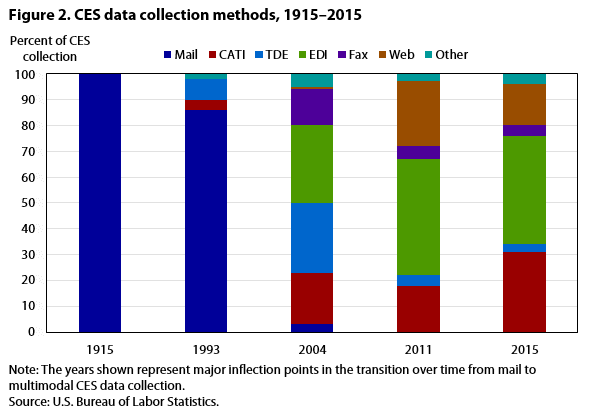 Changes in CES data collection methods over time are shown in figure 2.
Changes in CES data collection methods over time are shown in figure 2.
Beginning in the mid-1990s, BLS gradually assumed responsibility for nearly all new sample enrollments and monthly collections. One important reason for this development was that states had low initial response rates, and it was essential to raise these rates in support of the upcoming move to a probability-based sample. There were also benefits in cost, efficiency, and reduced respondent burden in the newer, centralized data collection methods. This was especially true for EDI, which allowed large multistate firms to report all of their worksites in one file. However, despite the increased centralization of data collection, federal–state partnership has remained an important part of the CES program.
Over time, the CES collection forms also evolved to meet the changing needs of the program. Major changes to the forms included the following:
- Addition of all-employee hours and earnings: These long-sought-after data items were added to the form in a redesign completed in 2005.
- Addition of two pay groups: To improve the ease of collecting payroll and hours data, CES redesigned its form to allow each firm to report separately for two pay groups (e.g., production workers paid weekly and other staff paid biweekly). This change also simplified the process of normalization, in which all data are converted to a 1-week equivalence, and was critical to the success of the all-employee hours and earnings initiative.
- Inclusion of tips in the CES payroll definition: In 2007, CES began including tips in its payroll definition for the service-providing industries. (Historically, there had been some ambiguity around whether tips should be included or excluded.) On forms used before the addition of all-employee hours and earnings, the reporting of tips was requested only from wholesale and retail trade establishments.
As the CES survey gradually replaced mail collection with an array of electronic collection methods, the standard CES forms were adapted to be more compatible with the new methods. For example, the traditional collection form is no longer used in EDI collection; instead, respondents are provided a booklet with data items and definitions, along with the specifications for developing an electronic file for reporting CES data items.9
Benchmarking
In the late 1920s, Federal Reserve statisticians noted that, when compared with data from the biennial Census of Manufactures, CES data on manufacturing employment exhibited a downward bias. CES was urged to adjust, or “benchmark,” its data to the census data. The first such benchmark was completed and published in 1935, with employment data being republished for 1923–29. The revision was very large by modern standards, approximately 12 percent.
Another development in 1935 was the passage of the Social Security Act, which established the Unemployment Insurance (UI) program. Employers were required to regularly report employment and payroll data to the state employment security agencies. This reporting requirement provided a more timely, near-universe employment count that could be used in benchmarking, and CES adopted UI employment data as its primary benchmark source. In 1940, CES published its first UI-based benchmark for selected industries and, in 1949, the first comprehensive UI-based benchmark was completed and published. Newly expanded UI-based data made it possible to directly benchmark all levels of industry detail.
In 1982, CES began benchmarking every year, on a regular schedule, to a UI-based benchmark. This practice fulfilled one of the recommendations of the 1979 National Commission on Employment and Unemployment Statistics. Before that time, delays in UI data processing and occasional changes in UI coverage meant that benchmarks were released at different times of the year and, in some years, the benchmarking process was delayed and a multiyear revision released at a later time.
Between 1982 and 2004, the national benchmark revisions were released in June of each year, with one exception. In 1990, in order to complete a major SIC revision and historical reconstruction project, CES delayed the national benchmark release until September. Improvements in the speed of processing of UI data from the BLS Quarterly Census of Employment and Wages (QCEW)—previously known as ES-202—allowed CES to advance its publication date from June to February, beginning in 2004.
The CES program started to announce a preliminary benchmark revision in December 1991, when some users and media began predicting the size of the CES benchmark revisions on the basis of the release of preliminary first-quarter QCEW figures. Over time, the announcement was moved up—first to November, then to October—and currently is released in September. The earlier dates were made possible thanks to the speedier compilation of the QCEW data, which are the primary source for CES benchmarking. The timing of the September announcement now coincides with the BLS publication of the preliminary first-quarter QCEW data.10
Birth/death estimation
Because the CES sample is not continuously updated, there is an unavoidable lag between the time an establishment opens for business and the time it becomes available for sampling. Since new firm births generate a portion of employment growth each month, nonsampling methods must be used to estimate this growth.
Before CES implemented a probability sample, which was phased into production between June 2000 and June 2003, the program used a procedure known as “bias adjustment” to account for employment changes due to business births and deaths. However, this procedure attempted to correct for all sources of bias in the monthly sample-based estimates, not just the contribution of business births and deaths. Using “bias factors,” CES basically modeled the net difference between the historical CES and QCEW employment levels and projected that difference forward, in an attempt to minimize future CES benchmark revisions. The regular use of bias adjustment began in the mid-1970s.
Internal CES research culminating in the late 1990s showed that a key assumption in bias adjustment—the stability of QCEW–CES differences—did not hold consistently, especially when employment reached a turning point or a major change in trend. With the introduction of the new probability sample, CES had an opportunity to implement a new method of modeling the employment change resulting from business births and deaths.
CES has found that the relationship between business births and business deaths is fairly stable and largely offsetting. Employment change at failing establishments is captured by BLS, either through those establishments’ nonresponse or by BLS treating them as nonrespondents when they do respond. Because employment effects from business deaths are assumed to approximate those from business births, the noninclusion of business deaths is assumed—for the most part—to offset the employment effects of the birth of businesses that have not yet been included in the CES sample frame.
Employment losses from business deaths, however, are not precisely equal to gains from business births. Therefore, it is necessary to model the remaining, or residual, employment effects coming from business births. Birth/death modeling uses standard “autoregressive integrated moving average” (ARIMA) techniques, whose inputs are 5 years of QCEW data in which each establishment is classified as a continuing unit, a birth, or a death. Using this process, CES is able to develop an estimate of monthly employment change that accounts for business births. Net birth/death employment is added to sample-based, not-seasonally-adjusted estimates each month.11
An important change to birth/death methodology occurred with the February 2011 release of January 2011 data. By that point, quicker availability of QCEW data had allowed for the quarterly forecasting of birth/death residuals, as opposed to the previous practice of annual forecasting. This change was intended to reduce revisions to the birth/death residuals.
Seasonal adjustment
CES data, like many time series, contain observable, regular seasonal fluctuations. Because these fluctuations can obscure trends in the data, it is often desirable to remove them.
In 1954, BLS began to prepare and publish seasonally adjusted estimates for the first time, using a technique known as the “standard ratio to moving average” technique. Before that time, seasonally adjusted data on industry employment had been published by the Federal Reserve Board. In 1980, CES began to use the U.S. Census Bureau’s X-11 ARIMA procedure12 for seasonal adjustment of national series.
From 1980 through June 1989, CES national series were seasonally adjusted with the use of factors updated annually as part of the program’s benchmarking process. From November 1989 through May 2003, these seasonal adjustment factors were updated semiannually. The change from annual to semiannual updating was made in order (1) to incorporate more current information, from the most recent sample-based estimates, into the seasonal adjustment factors and (2) to be consistent with the CPS national estimates for which the 6-month updating was already in place.
Also in the 1980s, CES introduced several special adjustments within its seasonal adjustment process, to correct for anomalies in the employment, hours, and earnings series. Most of these anomalies result from “calendar effects” in the not-seasonally-adjusted series. Calendar effects, often driven by the length of the time interval between observations, are recurring anomalies in time-series data that follow predictable patterns. Calendar effects distort the seasonally adjusted series and can result in false economic trend analysis. Examples of calendar effects are the variation in the interval (4 or 5 weeks) between survey reference periods, floating holidays such as Labor Day, and weather effects in the construction industry.13
In 1996, CES converted to the newly available X-12 ARIMA software in order to take advantage of new features that improved special adjustments for calendar effects and other anomalies.
In June 2003, simultaneously with the implementation of a major survey redesign, CES introduced a concurrent (i.e., monthly) recalculation of seasonal adjustment factors for national estimates, in order to incorporate the most up-to-date employment data into these factors. Research had shown that this recalculation would reduce revisions to estimates of seasonally adjusted over-the-month employment changes that occur with benchmark revisions.14
Before the introduction of concurrent seasonal adjustment for national series in June 2003, CES published the projected seasonal adjustment factors for future months as soon as they were produced. This practice began because, in the early days of seasonal adjustment, some users were concerned about the legitimacy of the seasonal adjustment process and sometimes even questioned whether the process was a method to “manipulate” the data. Publishing the factors ahead of time helped mitigate these concerns.
Conclusion
From its humble beginnings a century ago, the CES program has evolved into one of the world’s most prominent statistical surveys. Starting with a modest release of employment and gross payroll data for four industries, drawn from a few states, CES has grown to cover the entire nonfarm economy, publishing a wide variety of data on employment, hours, and earnings. Ongoing quality improvements—such as benchmarking and birth/death modeling—have served to bolster confidence in the accuracy of CES data. At the 100-year mark, the CES program’s accomplishments are many, but the important work of providing current, relevant data on the U.S. economy goes on, and CES has moved boldly into its next century.
Notes
1 The Current Employment Statistics (CES) program, which provides detailed industry data on employment, hours, and earnings of workers on nonfarm payrolls, is a monthly survey of about 143,000 businesses and government agencies, representing approximately 588,000 individual worksites. For more information on the program’s concepts and methodology, see “Technical notes for the Current Employment Statistics survey” (U.S. Bureau of Labor Statistics), http://www.bls.gov/web/empsit/cestn.htm. To access CES data, see “Current Employment Statistics—CES (national)” (U.S. Bureau of Labor Statistics), http://www.bls.gov/ces.
2 Historical documentation for the CES program is incomplete. The author has pieced together the facts as accurately as possible, using limited CES historical documentation.
3 The North American Industry Classification System (NAICS) classifies establishments into industry groups on the basis of the similarity of their production processes. NAICS was collaboratively developed by agencies representing Canada, Mexico, and the United States. The use of common industry definitions facilitates economic comparisons and analysis among the three countries, and the production-oriented nature of the classification system maximizes the use of industrial statistics in the production of information on inputs and outputs, productivity, industrial performance, and other economic data.
4 Derivative series are data series derived from basic employment, hours, or earnings data. The average weekly earnings derivative series, for example, is the product of average weekly hours and average hourly earnings.
5 Probability sampling is the technique of randomly selecting a subset of a population, with the sample then being used to represent the entire population. The randomness of selection ensures that every individual has an equal chance of selection and, therefore, is representative of members of the population who are not selected.
6 “Analysis of BLS-790 sample with a proposal for a new sample design” (U.S. Bureau of Labor Statistics, June 1963).
7 Quota sampling is a nonprobability type of sampling in which a sample is chosen from specific, mutually exclusive subgroups on the basis of prespecified characteristics. Sample units are then selected from each subgroup. In the case of CES estimates, the subgroups were state, detailed industry group, and establishment size.
8 In the benchmarking process, sample-based CES estimates are reconciled with employment counts drawn primarily from state unemployment insurance (UI) records. Because about 98 percent of all U.S. employing businesses must pay UI premiums for their workers, these records provide a near-universe count of employment. Other sources are used for workers not covered by UI.
9 For a more detailed explanation of CES data collection, see “One hundred years of Current Employment Statistics data collection,” Monthly Labor Review, January 2016, http://www.bls.gov/opub/mlr/2016/article/one-hundred-years-of-current-employment-statistics-data-collection.htm.
10 Detailed information on the CES benchmarking process can be found athttp://www.bls.gov/web/empsit/cestn.htm#section6b and http://www.bls.gov/ces/tables.htm#benchmark.
11 Detailed information on the CES birth/death model can be found athttp://www.bls.gov/web/empsit/cestn.htm#section5c and http://www.bls.gov/web/empsit/cesbd.htm.
12 For a description of the X-11 ARIMA procedure, see Julius Shiskin, Allan H. Young, and John C. Musgrave, “The X-11 variant of the Census Method II seasonal adjustment program,” Technical Paper No. 15 (Bureau of the Census, February 1967), http://www.census.gov/ts/papers/ShiskinYoungMusgrave1967.pdf.
13 Detailed information on CES seasonal adjustment can be found athttp://www.bls.gov/web/empsit/cestn.htm#section5.
14 “Concurrent seasonal adjustment for industry employment statistics” (U.S. Bureau of Labor Statistics, October 21, 2002), http://www.bls.gov/ces/cescsapdf.pdf.
~~~
John P. Mullins (mullins.john@bls.gov) is an economist in the Office of Employment and Unemployment Statistics, U.S. Bureau of Labor Statistics.
